DIAMOND 💎 (DIffusion As a Model Of eNvironment Dreams) is a reinforcement learning agent trained entirely in a diffusion world model. The agent playing in the diffusion model is shown above.
DIAMOND's diffusion world model can also be trained to simulate 3D environments, such as CounterStrike: Global Offensive (CS:GO).
Abstract
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner.
Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics.
However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning.
Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling
discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams),
a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make
diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance.
DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained
entirely within a world model. We further demonstrate that DIAMOND's diffusion world model can stand alone as an
interactive neural game engine by training on static Counter-Strike: Global Offensive gameplay.
To foster future research on diffusion for world modeling, we release our code, agents and playable world models at
https://github.com/eloialonso/diamond.
CS:GO DIAMOND 💎 Diffusion World Model Demonstrations
All videos generated by a human playing with keyboard and mouse inside DIAMOND's diffusion world model, trained on CS:GO.
To play our Atari world models:
python src/play.py --pretrained
For our CS:GO world model:
git checkout csgo
python src/play.py
How does it work?
We train a diffusion model to predict the next frame of the game.
The diffusion model takes into account the agent’s action and the previous frames
to simulate the environment response.
The diffusion world model takes into account the agent's action and previous frames to generate the next frame.
The agent repeatedly provides new actions, and the diffusion model updates the game.
The diffusion model acts as a world model in which the agent can learn to play.
Autoregressive generation enables the diffusion model to act as a world model in which the agent can learn to play.
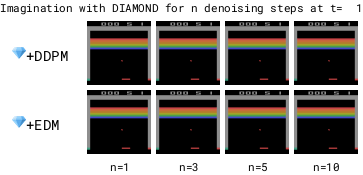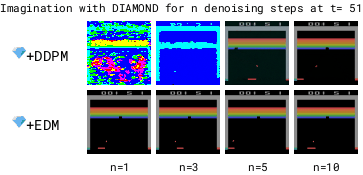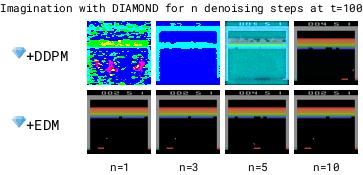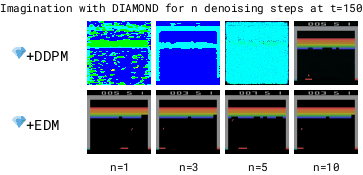
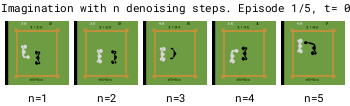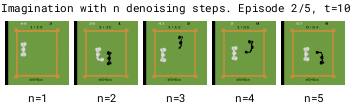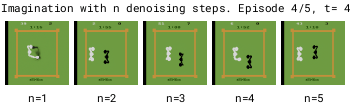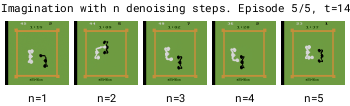
To make the world model fast, we need to reduce the number of denoising steps.
We found DDPM (Ho et al. 2020) to become unstable with low numbers of denoising steps.
In contrast, we found EDM (Karras et al., 2022) to produce stable trajectories even for 1 denoising step.
The DDPM-based model is unstable for low numbers of denoising steps due to accumulating autoregressive error, while the EDM-based model remains stable. Lower denoising steps enables a faster world model.
But in Boxing, 1-step denoising interpolates between possible outcomes and results in blurry predictions for the unpredictable black player.
In contrast, using more denoising steps enables better selection of a particular mode, improving consistency over time.
Larger numbers of denoising steps n enable better mode selection for transitions with multiple modes. We therefore use n=3 for Diamond's diffusion world model.
Interestingly, the white player's movements are predicted correctly regardless of the number of denoising steps.
This is because it is controlled by the policy, so its actions are given to the world model. This removes any ambiguity that can cause blurry predictions.
We find that diffusion-based DIAMOND provides better modeling of important visual details than the discrete token-based IRIS.
DIAMOND's world model is able to better capture important visual details than the discrete token-based IRIS.
Training an agent with reinforcement learning on this diffusion world model, DIAMOND achieves a mean human-normalized score of 1.46 on Atari 100k (46% better than human); a new best for agents trained in a world model on 100k frames.
Scaling to CS:GO
To apply DIAMOND's diffusion world model to CS:GO, we made the following changes:
No RL: We used a fixed dataset of 87h of human gameplay instead of data collected with an RL agent.
Two-stage pipeline: We perform dynamics prediction in low resolution, before upsampling with a second model, reducing training cost.
Scaling: We scaled up the diffusion model from 4.4M parameters for Atari to 381M for CS:GO (including 51M for the additional upsampler).
Stochastic sampling: We used stochastic sampling for the upsampler to improve visual generation quality (not necessary for the dynamics model).
Our model was trained in 12 days on an RTX 4090, and can be played at ~10 FPS on an RTX 3090.
Limitations
There are still many limitations of our model, some of which are shown below.
Representative failure modes of 💎 DIAMOND's diffusion world model.
We expect many of these aspects of our world model to improve by further scaling up data and compute. However, scaling would not solve everything, such as those due to the limited memory of our model.
One interesting limitation is that our model enables multiple jumps in a row by generalizing the effect of a jump on the geometry of the scene.
The model does not learn that this should not be possible, since successive jumps do not appear often enough in the training data.
💎 DIAMOND's model allows multiple jumps, even though only single jumps should be possible.
@inproceedings{alonso2024diffusionworldmodelingvisual,
title={Diffusion for World Modeling: Visual Details Matter in Atari},
author={Eloi Alonso and Adam Jelley and Vincent Micheli and Anssi Kanervisto and Amos Storkey and Tim Pearce and François Fleuret},
booktitle={Thirty-eighth Conference on Neural Information Processing Systems}}
year={2024},
url={https://arxiv.org/abs/2405.12399},
}